CallMePro CS 175: Project in AI (in Minecraft)
Sample Video
Summary
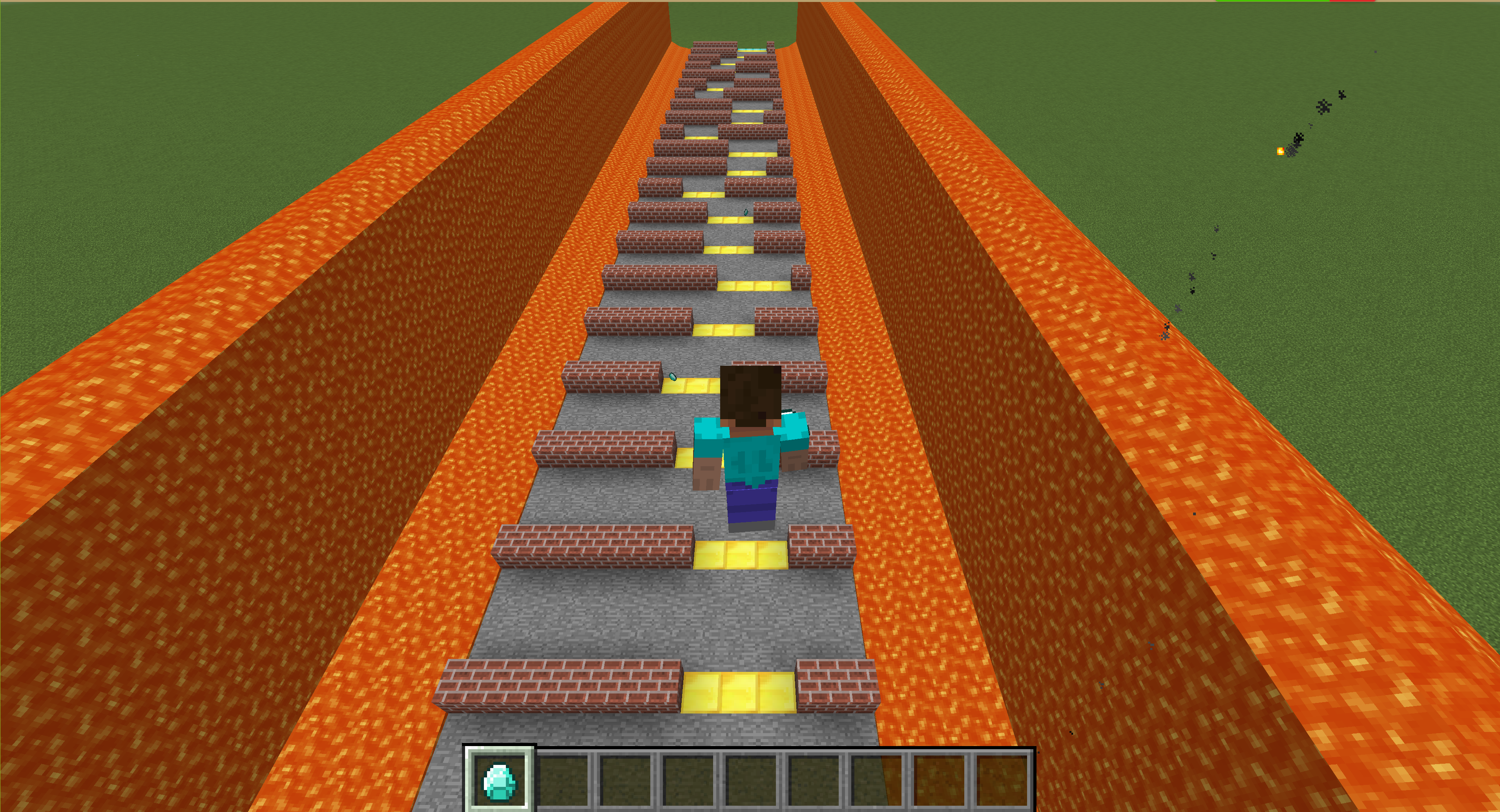
At the very beginning, our initial idea was to make a mini-game similar to Flappy Bird in minecraft and train a AI to reach the destination. But we found that with our current knowledge, this is a very challenging thing. So we changed from avoiding vertical obstacles to avoiding horizontal obstacles. There is deadly lava on both sides of the road, which prevents players from getting around these obstacles from both sides. We also add some random diamonds with bonus points to the map. Actually, if you look down from the air, the map design is similar to flappy bird. Now the player will not die when hitting the wall, but the more steps used, the lower the reward will be. If a player not complete within a certain number of steps, it will be considered a failure too. The difficulty of the map can be changed in the future, such as increasing the complexity of obstacles, laying deadly lava on the floor, making the path longer, etc. We may continue to add interesting elements to make this project more complete.

Approach
In this project, we are using PPO to train our agent that make him perform better. The PPO algorithm is a new type of Policy Gradient algorithm. The Policy Gradient algorithm is very sensitive to the step size, but it is difficult to choose a suitable step size. If the difference between the old and the new strategy changes during the training process is too large, it is not conducive to learning. PPO proposes a new objective function that can be updated in multiple training steps in small batches, which solves the problem of difficult to determine the step length in the Policy Gradient algorithm. The main idea of the algorithm is to accept the state s, output the action probability distribution, sample the action in the action probability distribution, execute the action, get a reward, and jump to the next state. After we get the index of action, then we will make action_dict to be a parameter of sendCommand.
We can collect a batch of samples after repeat these steps, and then use the gradient descent algorithm to learn these samples. A big improvement of PPO is to convert the On-policy training process in Policy Gradient into Off-policy. There are two probability density functions are written as p(x) and q(x). And p(x)/q(x) is called the ratio of the probability of taking the current action to the current state of the new and old strategy. In other words, the action is discrete, the output is a set of discrete probability distributions, the action is selected based on this probability distribution. We can fully sample the old policy, and then improve the new policy. This process can be repeated N times in a round instead of 1 time.
The gradient of the average reward value for N rounds:
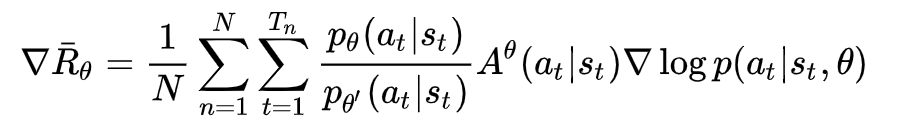
In the actual training process, there will be an operation on the clip:
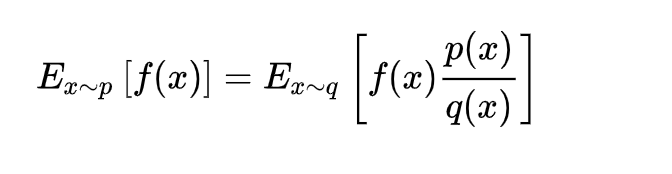
Approach
Actions of agent
1. Moving forward for 1 block.
2. Moving left for 1 block.
3. Moving right for 1 block.
Reward Functions
1. Reward = 10 when agent collecting a diamond on the floor.
2. Reward = 10 when agent through a gap.
3. Reward = 100 when agent touchs destination line.
4. Reward = -1 for every steps agent move on stone.
5. Reward = -10 when agent die from lava.
Evaluation
Qualitative:
For our project, the goal for the agent is to approach the destination with the least number of steps to avoid more deductions. Because the less deduction the agent gains, the higher rewards he gets. Before reinforcement learning, the agent’s movement looked a bit dumb, since he would get stuck in front of the obstacle and move left and right repeatedly. And in many cases, he would swim in lava. And even if he passes the obstacle, it is difficult for it to reach the destination within the maximum number of steps per episode. However, after learning for a half-hour, the agent approaches the destination successfully sometimes, but the rewards it got still not good as expected. Therefore, the agent should try to reduce the steps it uses to approach the destination, since the more steps he used, the more rewards he lost because every second before reaching the destination, the agent will be punished. After learning for 2 hours, the agent could reach the destination line every time, and gain more and more rewards. The agent becomes smart enough to pass all gaps, and be able to identify which side the gap is when encountering a wall.
Quantitative:
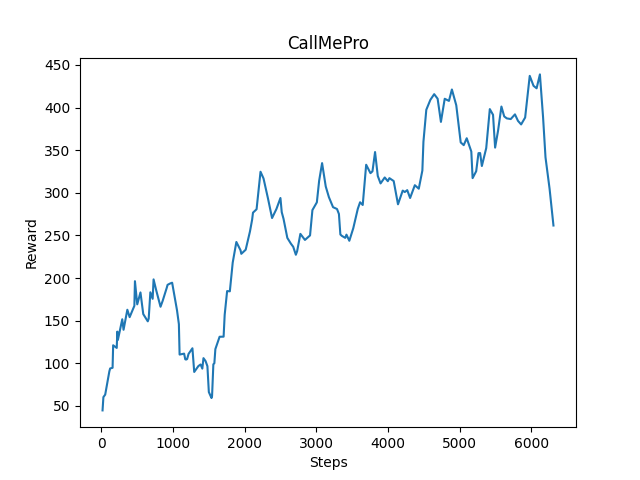
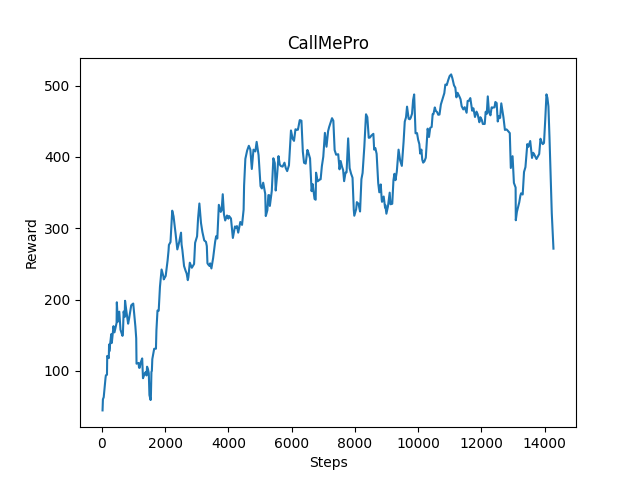
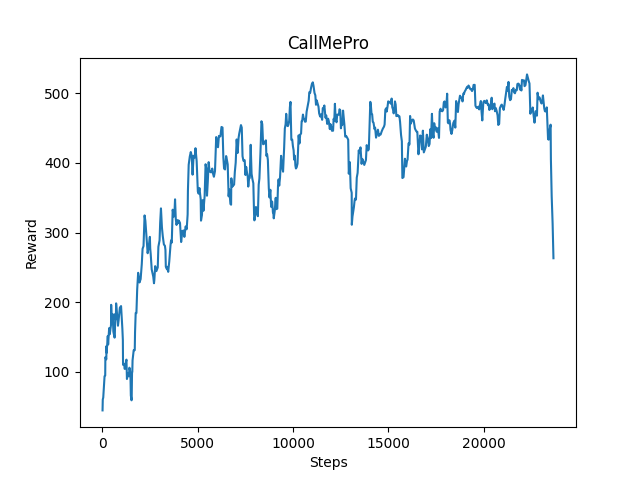
From the following three pictures, we know that the purpose of this program is to allow agents to get more rewards. In these three return graphs, we can clearly see that after a lot of training, the agent is getting more and more rewards. In the agent’s course of action, the agent can be rewarded by passing gold blocks and get diamonds, and every step the agent takes and falling into the lava will also cause corresponding punishment to the agent. The most important thing is that passing the destination line will give the agent a lot of rewards, so the agent is motivated to pass each gold block, get more diamonds, and use the fewest steps to reach the finish line. Through the three return graphs, we can see that the speed of the agent’s advance is increasing, The agent is guarantee to pass this map every time. However, after 14000 steps, the progress of the agent is not so obvious. This might because the map is too simple for the agent now.
After training 6000 steps:
After training 14000 steps:
After training 20000 steps:
Remaining Goals
Until this status report, we have not implement more maps with different difficulty. For example, the length of the path is a constant 100 now, and we may increase it in the future version. Furthermore, the only obstacle is the brisk block now, so we may add some other obstacles to increase the difficulty of the game. We may also add some penalties policy to improve the effectiveness of the reinforcement learning. We may also put more interesting element. For example, traps on the ground or arrows from both sides of the path. On the other hand, we also hope to implement some more useful algorithms to make the agent’s actions more smooth and realistic.
The ultimate goal of this project is to approach the score of human control as much as possible, or even exceed the score of human control. Therefore, we should have completed the optimization of all algorithms, and passed enough time and steps to train the agent, in order to make him reach the best condition. After that, we may invite some friends to play it and get the mean score. Then see whether the agent can approach it or exceed it.
Challenges
The challenge we are facing right now is when the agent has collected some diamonds but then he died from swimming in lava, these diamonds would leave in where he died. However, after resetting the map, these diamonds were still in there. We need to fix this error to make these diamonds disappear when the map is reset. Because resetting map should clear all the items from the previous episode, and then generate a brand new episode.
Another problem we need to fix is the agent will not take the initiative to pick up diamonds on the gold block yet. Because each diamond worth 10 points, if the agent wants to gain as much as rewards, it should pick up more diamonds after learning. But right now, even after training for 3 hours, the agent still could not pick up diamonds initiatively to improve his reward points. This problem might be more difficult. So we might need to optimize our algorithm in the future.
The most challenging part for us is the time zoom and the number of team members. We are back to China, we often need to get up in the early hours of the night to attend class, which often affects our sleep, so that it affects our thinking ability and reaction speed. This also leads to another problem, that is, we must find a third teammate who is in the same jet lag with us, because this will facilitate our communication, otherwise it will often happen that we can not find each other. Therefore, completing the homework by two people greatly increases the workload and difficulty. We also hope that in the future work, we can allocate our time arrangements well to improve our efficiency.